本日は、英語コーパス学会のワークショップで、「はじめてのXML」のお話をさせていただきました。コンセプトとしては、「とりあえずXMLはどういう風に良いものなのかを見ていただき、自分でやってみたい人はあとで録画をみていただく」ということで、パワポスライドとGoogle Colabを準備してちゃかちゃかお話をしました。このようなコンセプトにしたのは、コーパス研究者でタグを邪魔だという人を結構拝見したことがあったということと、ごく最近にも以下のようなお話もありましたので、使い方以前に、「タグがついていると何がうれしいのか」をもう少し明白に共有した方がよいのではないか、ということがありました。
「タグ付きのコーパスデータは、正規表現を書けない言語系・教育系の人にとって使いにくいのでは?」とカキーン会議で話題になり、プレーンテキストのバージョンも作ることに。
— langstat (@langstat) 2022年9月30日
当該コーパスのタグ仕様は、既存のコーパスに準拠しているので、、、20年近く前に書いたPerlプログラム()で消せるはずw
さて、このワークショップの際は、英語コーパス学会の方々に聞いていただくので、おそらくなるべくカタいものを使った方がよいのではないかと思い、BNC (British National Corpus)を事例としてご用意したのですが、
せっかく作ったので公表したい
⇓
しかしBNCはマニアックすぎるのでは
⇓
そういえばノースイースタン大学のマーティン・ミュラー先生がシェイクスピアの品詞情報タグ付きコーパスを公開しておられたぞ
ということで、素材をシェイクスピアのテキストに入れ替えて、TEI/XMLファイルがあるとどう便利なのか、という簡単なPythonプログラムをGoogle Colab上に作成してみました。これは、ボタンクリックすれば実行されるものですので、プログラミングをまったくできなくてもお試ししていただくことができますが、解説に関してはPythonを少し勉強したことがある人向けのもので、細々とプログラムの中に書き込んでおります。でも、むしろ、これをみてPythonを勉強してみようという気持ちになってくださる人がおられたら、それもとてもうれしいことです。
Google Colabでは、とにかく以下の「セルを実行」ボタンをクリックすると、そこに書かれたプログラムが実行されるようになっています。
上記のGoogle Colabでプログラムを実行していただくと、なるほど、という感じになってくださるのではないかと期待しております。
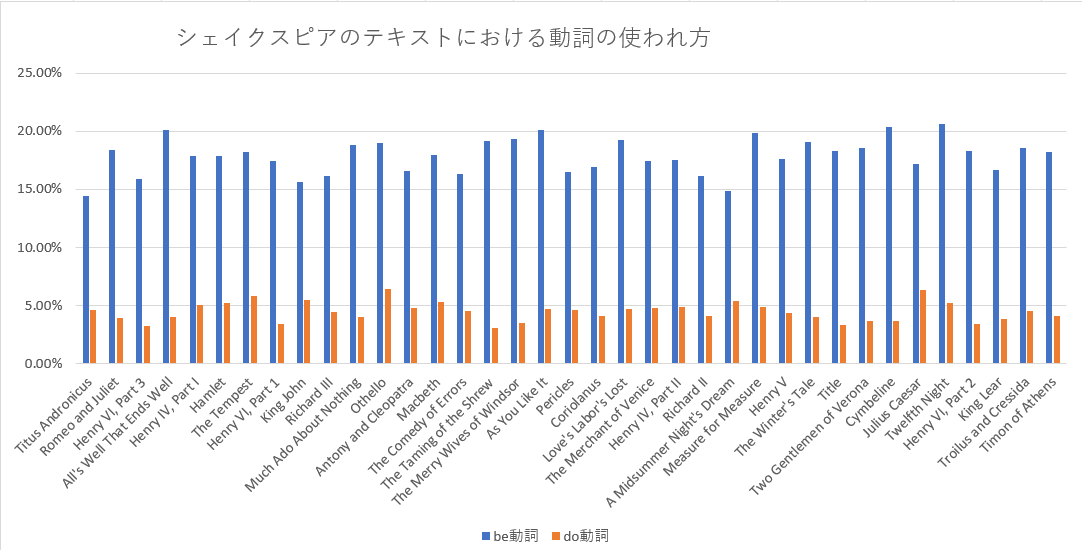
最後の方に用意してある「5.3.各ファイルにおける動詞の中でのbe動詞とdo動詞の割合を数えてみる」の結果をエクセルに持ち込んでグラフ表示すると冒頭の画像のような感じになります。
Google Colabに用意したものは、値を変えるだけでも色々なものを数えたりできますので、興味が沸いてきたら、「ファイル」メニューから「ドライブにコピーを保存」で自分のドライブにコピーしてから色々と試してみてください。
※この記事は「「人文学のためのテキストデータ構築入門」フォローアップサイト」の一環です。
