TEI用ビューワにローカルPC上の画像を読み込んで拡大縮小させつつ領域を画像上に表示したい、というニーズが最近増えてきました。IIIFなら簡単なのですが、ローカルPCだと微妙に難しいところがあります。Webブラウザのセキュリティが色々細かくなってきているので、それをどうパスするか、という課題もあります。そのあたりをクリアしたTEI用ビューワを最近2つほど作成しました。日本近代文学の草稿研究向けのものと、和歌・歌合研究のためのものです。基本は同じですが、今のところそれぞれ少しニーズが異なるので、ベースは同じで、それぞれにカスタマイズしながら作っています。
なお、ローカルPC上の画像を読み込みたいというニーズは、つまり、画像を公開できないということなので、ここでデモを表示することもできないのですが、和歌・歌合研究用のものは古典の再生シンポジウムで公表しましたので、そちらをご覧になった人は覚えておられると思います。あのようなものの作り方、ということになります。
さて、ローカルPC上で画像を表示するなら、TEIのファイルや表示プログラムもローカルで動くようにしないとうまくいきません。ここで、ブラウザセキュリティ的に簡単なのはローカルでHTTPサーバを立ち上げるという方法なのですが、HTTPサーバの立ち上げは、少し慣れてないとハマり要素の一つになってしまいがちで、たとえば「誰かに操作してもらう」というような場合に結構ややこしいことになりがちです。そこで、別案を考えます。
ブラウザセキュリティ的にややこしいのは、ビューワのプログラム(ここではJavascriptを前提としています)からTEIのXMLファイルを読み込むという局面です。普通にローカルのTEIファイルを読み込もうとしてもブラウザにブロックされて読み込めない場合が多いのです。そこで、TEIのXMLファイル読み込みをブラウザのフォームからアップロードする形でWebブラウザに渡すという方法があり得ます。この場合、アップロードした時点でJavascriptで読み込むことができますので、割とすんなりと読み込むことができます。開くたびにアップロードするのがちょっと面倒ですが、デモ用と割り切っていただくということで…
さて、そうなってくると、まずは、TEIのXMLファイルをJavascriptで読み込む方法をとりあえず押さえておく必要がありますね。これは以下のようなスクリプトで簡単にやってみましょう。
<!doctype html> <html lang="ja"> <head> <!-- Favicons --> <script src="https://code.jquery.com/jquery-3.6.0.js"></script> </head> <body> <h1>TEIビューワ ver.0.1</h1> <div id="text_body" style="writing-mode: vertical-rl" > <div id="body_result" style="overflow-x: scroll;width:1000px;height:600px;padding:10px;"><!--この id="body_reusult"にデータを表示する--> </div> </div> <div id="input1" style="padding:10px">本文:<br/> <input class="file_input1" type="file" multiple="" class="btn btn-default"> </div> <script> $( function() { $('.file_input1').change(function(){ for (var i = 0; i < this.files.length; ++i){ if (this.files[i].type == 'text/xml'){ var reader = new FileReader(); reader.onload = function(e){ var xmldata = $.parseXML(e.target.result); // TEI/XMLファイルの内容をXMLでパースしてxmldata変数に代入 $(xmldata).find('titleStmt').each(function(){ $(this).find('title').each(function(){ // TEI/XMLのデータからタイトルを取得 $('#body_result').append('<span style="font-weight:bold">'+$(this).html()+'</span>'); //タイトルを<span>タグに入れてid="body_resut"のエレメントに付与 }); $(this).find('author').each(function(){ // TEI/XMLのデータから著者名を取得 $('#body_result').append('<div class="author">'+$(this).html()+'</div>'); // 著者名を<div>タグに入れてid="body_resut"のエレメントに付与 }); }); // ここに次のスクリプトを追加 } reader.readAsText(this.files[i], "utf-8") } } }); }); </script> </body> </html>
とりあえずこれをコピペしてhtmlファイルを作成して、Google chromeで開いてから何らかのTEI/XMLファイルを読み込ませてみてください。そうすると、タイトルと著者名が表示されるはずです。たとえば以下のものは、こちらの『走れメロス』のファイルを読み込ませてみた例です。
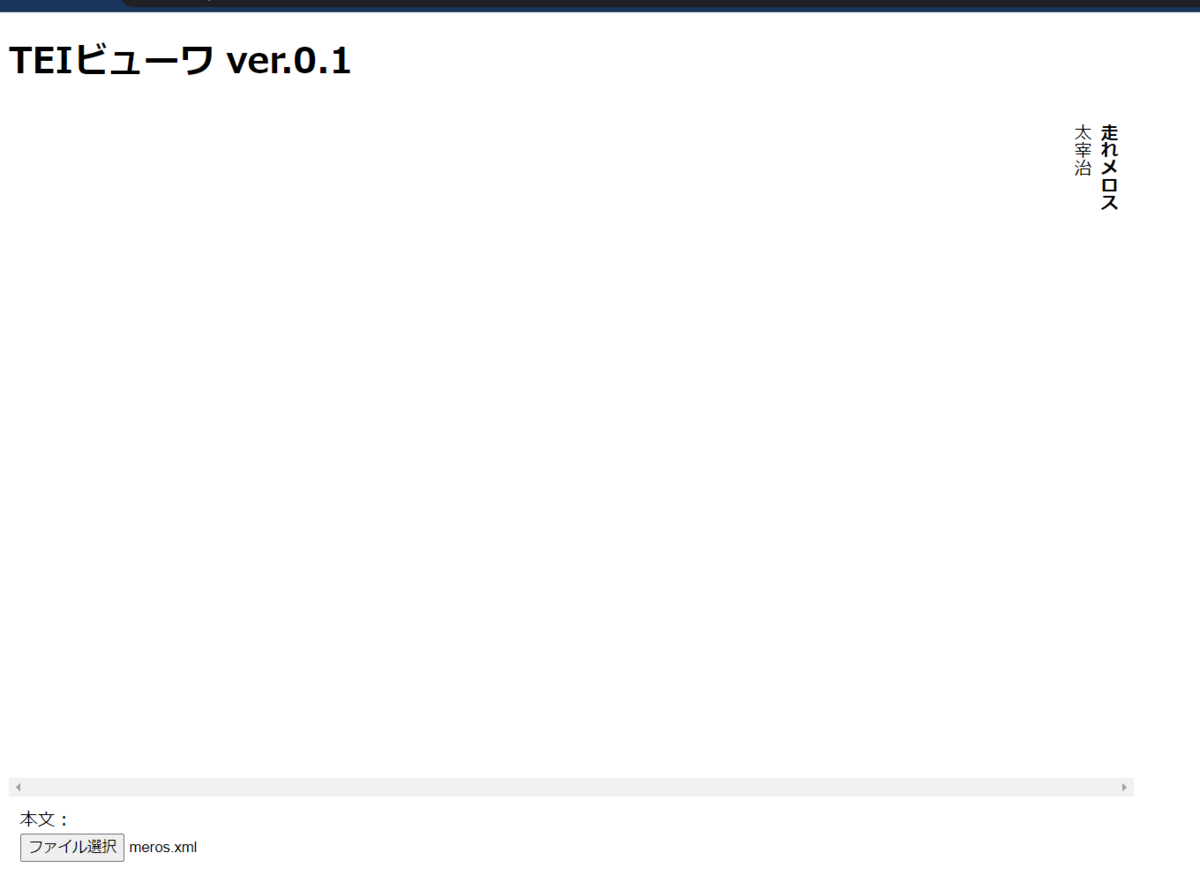
これだけでは本文がないですね。そこで本文も表示させてみましょうか。以下のスクリプトを「ここに次のスクリプトを追加」と書いてあるところに追加して、保存⇒Webブラウザで再読み込み⇒TEI/XMLファイルの読み込み、をさせてみましょう。
$(xmldata).find('text').find('body').each(function(){
$('#body_result').append($(this).html());
});
ちなみに、このスクリプトは、jQueryというやや古いが比較的簡単な記法を用いて書いています。冒頭の$(xmldata) はjQueryが提供している色々な機能を用いてデータを操作できるものです。これに対して find('text') とついているのは、下位要素のなかでtextエレメントを探す、という意味です。ここに、.find('body')をつけると、さらに下位の要素のなかのbodyエレメントを探す、という意味です。そして、 .each(function... とついているのは、bodyの内容が複数であることを想定して一つずつ処理するということになります(PythonのBeautifulSoupとはfindの意味が異なりますのでご注意ください)。
そして、$('#body_result')は、HTMLファイルの中でIDがbody_resultであるものを指定しており、それに対して .appendを用いて続く括弧の内容を付与します。括弧の内容は $(this).html()となっていますが、これは bodyエレメントの内容として一つずつ処理されるものが$(this)に代入されることになっており、それに対して .html() をつけることでタグ付きデータを取り出すように指示しています。
ということで、うまくできていれば以下のように表示できているはずです。
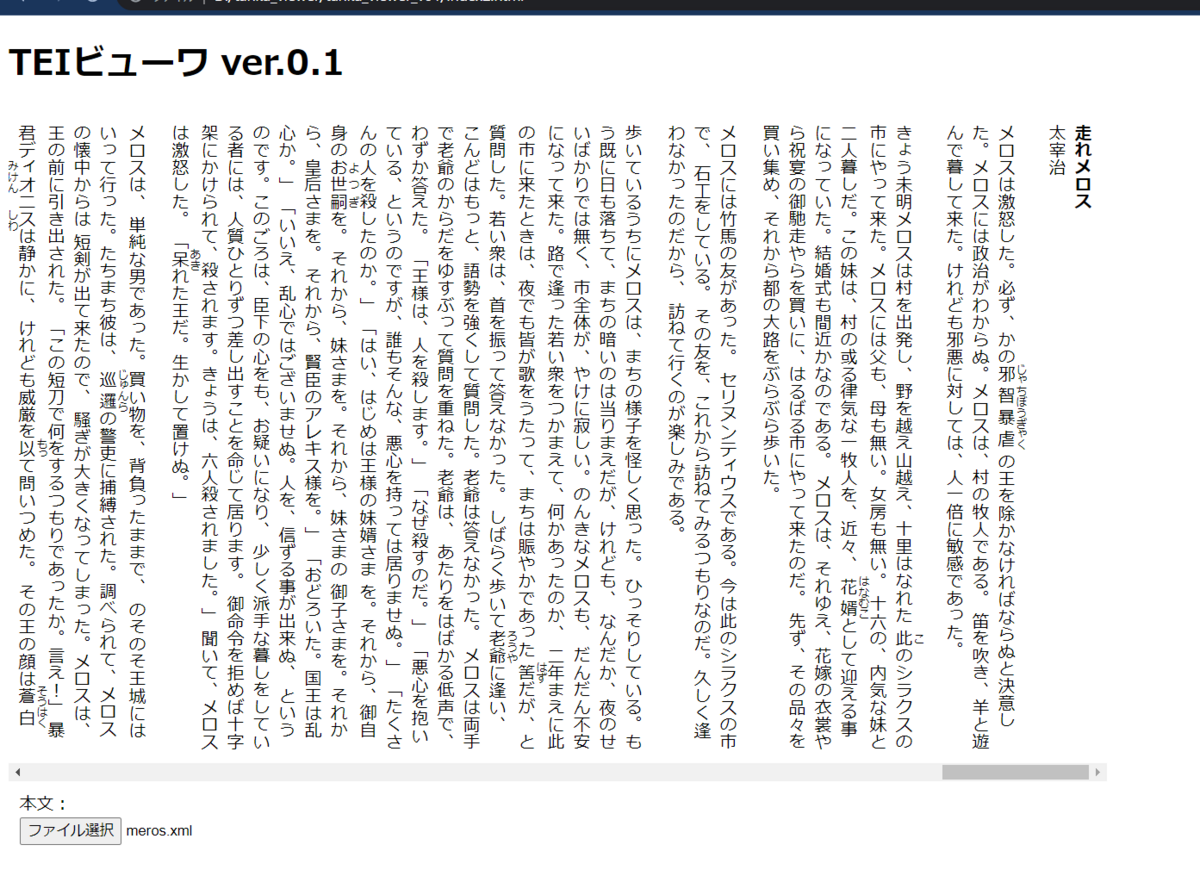
さて、これでTEI/XMLファイル中のタイトル・著者名・本文を取り出してHTMLファイルとして表示できるようになりました。このようにしてTEI/XMLのデータを取り出して処理できるようにすることで、ローカルPC上の画像ともリンクできるようになります。
準備編ということで、今回はここまでとします。