最近、サンスクリット写本のデータベースを作りました。といっても、文字起こししたテキストデータベースではなくて、 デジタル画像のデータベースです。世間ではむしろ「デジタルアーカイブ」と言った方が通りがいいでしょうか。
一人で作ったわけではなくて、メタデータを作ってくださった人と、デジタル画像を撮影してくださった企業、 撮影された画像を検品してくださった人、撮影等の費用を捻出するために助成金を取ってくださった人、 その助成金を出してくださった組織、といった色々なステイクホルダーがあり、また、そういったデジタルに 関することとは別に、この資料を集めてくださった人たち、大事に整理・所蔵してきた図書館の方々、という、 現物に関するステイクホルダーの方々もおられます。
私の役割は、そういった方々の間を回って話をしたり色々作っていただいたりしながら、 現物のサンスクリット写本の「デジタル代理物」としての データベース(デジタルアーカイブ)のシステム部分を構築した、ということになります。 ここでは、そのシステム構築の部分の話をちょっと書いておきたいと思います。
まずはじめに
この種のものを構築するときは、仕様書を書いて外注するのが一般的ですが、そもそも元になった資料の性質やとれるメタデータ等々、一通りきちんと 把握していないと良い仕様書は書けません。最近、和本に関してはIIIFの普及もありかなり標準化されてきているので割と簡単にできるようになって いるようにも思えますが、今回はちょっと事情が異なるかもしれないですし、そもそも外注する費用がちょっともったいないということもあり(それより 若手に色々作業してもらう謝金に回した方がいいと思うので)、自分で構築することにしました。
利用するソフトウェア
データの件数としては、公開当初は一部のみを先行公開ということでしたので100件に満たない数で、しかし最終的には数千件のデータを扱うことになります。 数千件ですと、今のコンピューティングであれば単にテキストファイルを用意して検索するだけでもいいのですが、AND検索、OR検索、NOT検索等の 各種検索に加えてソートをしたり等々といった色々な検索機能を拡張していくことを考えますと、そういう機能が充実しているソフトウェアに データを組み込んでしまった方が構築や改良が圧倒的に楽です。そこで、最近この種のことに使っている全文検索ソフトウェアApache Solrを今回も採用する ことにしました。
検索システムへの格納
どういうデータをここに載せて検索させるか、ということについては、相当悩みました。というのは、メタデータはTEI P5の形式で用意されており、そこからいかにしてうまく 必要なデータを取り出して便利に使えるようにするか、ということでした。似たようなこと(=TEIに準拠したメタデータで古典籍の書誌情報検索を提供)をしているサイトとしては、ケンブリッジ大学デジタル図書館がありましたので、あまり凝りすぎずに、ここでできていることを目指せばいいか…というくらいに考えていたところでした。ただ、難しかったこととして、基本的に、写本の一つの束の中には複数の経典が含まれていることが多く、写本の束と含まれている経典のどちらを基準としてデータを構築すべきか、ということについてかなり悩み、ちょうど、Apache SolrでNested Child Document機能が使えるようになったと知ったのでそれもかなり色々試してみたのですが、結局、どうもうまくいかない点がいくつかあって(苦闘の記録)、今回は諦めて、中に含まれている経典の単位、いわゆる子書誌を単位にしたデータ格納をすることにしました。ですので、すべての子書誌が親書誌の情報をそれぞれ有していて、検索後、表示等をする際には親書誌情報単位でまとめて表示する、という関係になっています。
IIIF対応のための作業
画像は、Phase Oneの1億画素のデジタルバックで撮影したものを、JPEG圧縮をかけたPyramid TIFF画像に変換しました。これはTIFF画像の時点では1枚あたり300MBくらいありますが、JPEG圧縮を結構かけているのでPyramid TIFFでのファイルサイズは18Mバイトくらいです。これを、IIP Image Serverを使ってIIIF Image API経由で閲覧できるようにしました。(詳しいやり方はこちら)ついでに、サムネイル画像作成もしたのですが、これはvipsthumbnail というLinuxのシェルで使えるプログラムで繰り返し処理をしたらさくっと終わりました。
その後、IIIF Presentation APIです。IIIF Presentation APIを用意するということは、すなわち、IIIF Manifestファイルを作成するということです。これは、やはりTEI P5に準拠したデータをなるべくよい感じで取り出して、metadeta フィールドに全部押し込んでしまう、というのが基本的な戦略です。TEI準拠で書かれたメタデータファイルと画像のデータやThumbnailなども組み込むPythonのスクリプトを作成して、これはそんなに難しくなくできました。スクリプトのひな形はこちらですが、もう少し整理できたら、今回新たに作成したスクリプトも公開したいと思っております。
Webインターフェイスの作成
さて、検索とIIIF対応画像・IIIF Manifestファイルは作成できました。次はWebインターフェイスです。Webインターフェイスは、凝り出すときりがないので、なるべく簡素に、Bootstrapのテンプレートの中でよさそうなものを使って見ることにしました。「Album」というのがありましたので、それを使ってみることにしたのですが、ただ見せるだけでは面白くないのではないか…と思ってきてしまい、少しだけギミックを作り込んでしまいました。
ちょっとしたギミックの作り込み
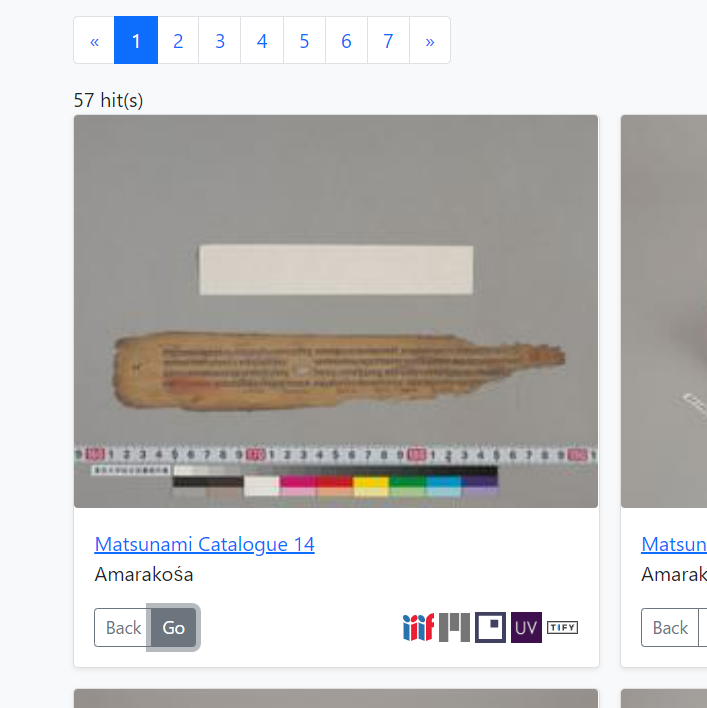
サムネイル画像の表示は、写本の束の単位で、トップページでも検索結果でもサムネイル画像が表示されるようにした上で、各サムネイル画像に代表的なIIIF Viewerで開くようにリンクアイコンを付けた上で、さらに、「Go」「Back」ボタンでそれぞれの写本のサムネイル画像を遷移できるようにして、さらに、写本の束のタイトルをクリックすると、表示されているサムネイル画像のページでIIIF Viewer (Mirador 3) が開く、という風にしました。また、IIIF Curation Platformでも、該当ページが開くようになっています。Universal Viewerはやりかたがよくわからなかったので諦め、TIFYは、やり方はわかったのですが n枚目という記述を独自形式で行わねばならず、ちょっと面倒だったのでやりませんでした。(でも30分も集中すればできると思いますが)。
というようなことで、このサムネイル画像表示にはちょっと凝ったのですが、なかなか楽しくて気に入っています。
反省点
ただ、反省として、この種のページを作るには、明らかにvue.jsのような仮想DOMを使った方が全体構成としては楽だったはずなのですが、vanilla JSがどうもよくわからないことがあって、しかしjQueryは何も考えずに普通に使えてしまうので、ついjQueryで書いてしまいました…。反省しつつ、vanillaの勉強をしなければと改めて心に誓ったのでした。