ここしばらく、国立国会図書館デジタルコレクション(NDLデジコレ)で公開されている『大日本仏教全書』という仏典叢書のインデックスを作成する作業に没頭しておりました。
『大日本仏教全書』は大正時代に刊行されたものなのですが、大変面白いもので、仏典叢書と書きましたが、仏教思想に関するものだけでなく、日本のお寺の寺誌とか史伝とか、鴨長明の佛敎説話集『発心集』なども入っていたりして、基本的に日本で書かれた仏教に関連する色々な資料の集成です。
これは、すでにマイクロフィルム化されていたらしく、NDLデジコレではそのマイクロフィルムをスキャンしてデジタル化したもので、全体的に画像が不鮮明で、戦前の旧字体で印刷されていることもあり、拡大表示しないと文字を判別できないことも結構あって、デジタル化資料としてはちょっといまいちなのですが、それでもWebで無料で読めるということは大変貴重なことなので重宝しております。マイクロフィルムの時点でモノクロだったようで、デジタル画像もモノクロ(グレースケール)なのですが、この資料に関してはモノクロでも問題ないのでその点は大丈夫です。
さて、資料をうまく扱えるようにするためには、とりあえず叢書に入っているテキストのリストを作りたいところです。幸いにして、NDLデジコレでは公開資料の目次を作成公開する作業を連綿と続けてきているようで、ありがたいことにこの『大日本仏教全書』でも目次がついています。そこで、これを自動的に取得すれば割と簡単にテキストのリストを作れるだろうと思っていました。
とはいえ、自動的に目次を取得するのってどうやったらいいんだろうか…と思って、NDLサーチのWeb APIの説明などを見てみても、どうもいまいちピンときません。そういえば、7年くらい前に、面倒になってHTMLを取得して解析するという原始的な方法を用いたことを思い出したのですが…うーん…と考えていて、ふと思い出したのが、最近導入されたIIIF Manifestファイルを見たときに「sc:Rageを取得すれば目次がとれるぞ」と思ったことです。
たとえば、 https://www.dl.ndl.go.jp/api/iiif/952681/manifest.json このようなIIIF Manifest URIで、"structures"以下に配列として入っている要素のうち、"@type": "sc:Range"の"label"を取得すれば確実に機械的に取得できます。JSON形式データなので、Python等でも関数一発でdict/listとして処理できるようになります。これはなかなか便利です。URLの"952681"が資料のIDなので、資料IDをリストして IIIF Manifest URIを生成して自動取得して…と、もう大丈夫ですね。ただ、NDLのサーバは非常に頑強ですが、それでも、あまり一度に大量に取得し過ぎないように気をつけてください。日本文化に興味を持っている世界中のみなさんと共同で使っているサーバですからね。
なお、話がよくわからない、というときは、Python3, JSON, スクレイピング、といったキーワードでググってみてください。Python3の勉強は自分でしてください。
せっかくの機会なので、以下に今回作ったスクリプトを貼っておきます。ここでは、NDLデジコレの資料IDのリストはディレクトリ名を使っています。というのは、すでに必要な画像を資料IDごとに作成したディレクトリに格納しているのです。たとえば、以下のような感じのディレクトリで作業しています。
[nagasaki@localhost dainihon]$ ls -d 95* 952681 952704 952727 952750 952797 952822 952845 952682 952705 952728 952751 952798 952823 952846 952683 952706 952729 952752 952799 952824 952847
で、スクリプトの方はこんな感じで、とりあえずJSONでデータ取得しています。この時点ですでにいくつか問題点に気づいていたので、少しだけ例外処理を入れています。
#!/usr/bin/python3 import glob import re import os import urllib.request import json import time #https://www.dl.ndl.go.jp/api/iiif/952686/manifest.json #p3 get_chapname.py > dh_sinindex.json arfiles = glob.glob('95*'); alltit = {} #113,114がNDLでは欠番なのでスキップしている。 alltit["name"]= "大日本仏教全書" alltit["id"]= "DNall" alltit["bv"]= "" alltit["children"]= [] vol_num = 1 title_num = 1 for file in arfiles: time.sleep(1) url = 'https://www.dl.ndl.go.jp/api/iiif/'+file+'/manifest.json'; req = urllib.request.Request(url) with urllib.request.urlopen(req) as res: titles = [] vol_name = {} title = {} manifest = json.load(res); if "structures" in manifest: structures = manifest["structures"] for range in structures: if "標題" != range["label"]: if "目次" != range["label"]: if "canvases" in range: cid = range["canvases"][0] range_title = range["label"] title = {} if file == "952806" and "巻之" in range_title: range_title = "本朝高僧伝"+range_title if file == "952825" and re.match(r'^巻', range_title): range_title = "東大寺雑集録"+range_title title["id"] = 'DN'+str(title_num); title["creators"] = [{"id":"c1","name":"","pname":""}]; title["name"] = re.sub(r'^一 ', '', range_title); title["bv"] = ""; title["canvasid"] = cid; title_num += 1 print (range["label"]) titles.append(title); title = {} else: title["name"] = re.sub(r'大日本仏教全書. 第.+?巻\s*', '', manifest["label"]) title["id"] = 'DN'+str(title_num) titles.append(title); title = {} title_num += 1 if vol_num == 113: vol_num = 115 vol_name["id"] = "DNV"+str(vol_num) vol_name["bv"] = ""; vol_name["url"] = url; vol_name["name"] = '第'+str(vol_num)+'巻' vol_name["children"] = titles; alltit["children"].append(vol_name) vol_num += 1 print (url); with open('dn_sindex.json', mode='w') as f: f.write(json.dumps(alltit, indent=2, ensure_ascii=False)) #print (alltit)
さて、データは取得できたのですが、これを見て、ちょっと修正が必要っぽいところがいくつかあることがわかったので、細々みていくと…結構大変だったのですが、 とりあえず一般的な話だけをしておきますと、『大日本仏教全書』は150冊ほどあるのですが、目次のルールが統一されていないようで、冊によって記述されている 階層が異なっているということがわかりました。目次に階層があるのですが、その記述の仕方が冊によってまちまちである上に、そもそも 冊によっては目次がないものもあるのです。ですので、そもそも統一的な目次データを作るためにはただ目次を入力するだけでは済まないという ことになります。入力作業は企業に発注したのか館内の方々がされたのかよくわかりませんが、どなたが作業するにしても、そもそも この叢書に関しては分担して作業するための「統一入力ルール」を作ることが困難であるということがこの点からすでに明らかでした。
それから、含まれているテキストごとに著者や編者がいて、目次にはそれが大体書いてあるのですが、親切にもそれが入力されている冊とされてない冊があって、 しかし、全体の状況からみると著者や編者を入力することは発注仕様には入っていなかったのではないかと想像されるので、入力してくださったかたの親切心を感じたところでした。
というようなことで、全体の構造を把握した上でデータを修正していくという作業をすることになりました。
きれいな階層構造データを処理するならJSON形式は大変お手軽ですが、手で細々修正するにはちょっと向いてません。JSONを便利に書けるエディタは色々ありますが、 データ形式を気にしながら細々書くのはやっぱり面倒です。そこで出てくるのはエクセル…と思いましたが、他の人と共有するなら最近はGoogle Spreadsheetの方が 便利です。しかも、デフォルトで正規表現置換が使えます。というわけで、データをタブ区切りテキストに変換して、Google Spreadsheetに読み込みです。
あとは、これを前提にしてデータを作っていくわけです。
目次は3段階に分けることにして、「本」「本に含まれるタイトル」「一つのタイトル中の章等」を基本にしました。それから、著者・編者については、 ざっとみて大部分が「撰」だったので、デフォルトは「撰」ということにして、それ以外のケースについては、人名+役割を記述することにしました。 ここでは一度に登場する人名が増えるごとにspreadsheetの列を増やすという方針で、最終的に最大3名ということで済みました。
目次に書かれたテキスト名は、基本的に、「何巻で構成されているか」ということが付記されています。たとえば
「日域洞諸祖伝二巻」
といった感じです。これは本来、カラムを分けて
日域洞諸祖伝|2|巻
という風にするのが理想的ですが、とりあえず後でそういう風に処理することを前提として、とりあえずは正規表現置換をしてみます。
検索文字列 ([^〇一二三四五六七八九十])([〇一二三四五六七八九十]+巻) 置換文字列 $1 $2
という感じで、半角スペースで区切っておきます。一括でやってしまうと意図しないものを区切ってしまうかもしれないので、一応、一つずつ見ながらやっていきます。 そうすると、一つのテキストが複数の冊にわたるものが結構ある上に、
『大日本仏教全書』vol. 10 ○○經疏巻1~10 『大日本仏教全書』vol. 11 ○○經疏巻11~15 △△經疏
という風になってしまっているものが散見されます。これは大正新脩大藏經だと大般若経だけなのですが、『大日本仏教全書』は1冊がそれほど大きくないために、 分冊されてしまいやすく、しかも、隙間があれば別のテキストを入れてしまうので、微妙にややこしいことになってしまうようです。
これはややローカルな事情ではありますが、これはいわゆる複数構造のオーバーラップという話ですので、似たようなことは他のデジタルデータでも 結構みられるのではないかと思います。
解決の方法は…と言えば、とりあえず今のところはインデックスを作っているだけで、階層ごとに用途がありますので、その用途にあわせて、 なるべく『大日本仏教全書』に沿ったルールで名付けていくことにしました。
それから、文字の扱いもちょっと変更してしまいました。NDLデジコレのデータは基本的に新字体に寄せてあって、一定のルール(JIS第二水準くらい?)に入らない文字は 「〓」になってしまっていますが、これを、Unicode準拠で、旧字体で書かれている漢字はなるべく旧字体で入力する、ということにしました。 実際のところ、検索する際はこちらの変換データを使って検索をかけるので、新字体旧字体どちらでもかまわないのですが、 それならば、とりあえずは元資料になるべく沿った形にしておこうということで、旧字体としました。たとえば、手元のvueアプリから抜粋すると、以下のような関数で検索用文字列を 生成して正規表現検索をしています。
getVarChars: function(e,sw){ //swを'reg'にすると正規表現検索用文字列が返る //swがそれ以外なら配列で各文字が返る var arChars = Array.from(e); var vChars = []; var vChar = []; var vCharLine = ''; arChars.forEach(function(ekc){ vChar = [ekc]; chars.forEach(function(ec){ // charsに、上記のmapping_char.jsonが入っている。 if (ec.u1 == ekc){ vChar.push(ec.u2); } else if (ec.u2 == ekc){ vChar.push(ec.u1); } }); if(sw == 'reg'){ vCharLine += '['+vChar.join("")+']'; } else{ vChars.push(vChar); } }); if(sw == 'reg'){ return(vCharLine); } else{ return (vChars); } },
Unicodeで漢字を探すときは、基本的にCHISE IDS漢字検索を使います。
これの便利なところは、「探している漢字部品を含む漢字」から目当ての漢字を高い確度で探せる、という点です。
たとえば、「潡」を探したければ「敦」で検索すればすぐにみつかる・・・というあたりは初歩的ですが、 「濬」を探したい時に、同じような漢字部品を持っている「叡」を検索すると以下のようにヒットします。ここで 赤丸をつけたところをクリックすると、今度はその部品で検索できるようになります。
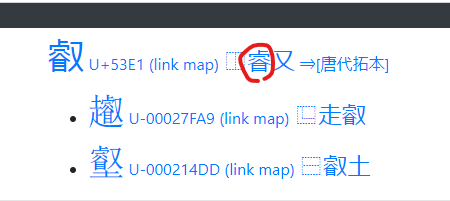
さらに部品を追加して絞り込み検索することもできますし、そのままリストから探してもOKです。 Unicodeの新しい文字まで入っているので、Unicode で限界まで資料に沿った文字を表示させたいという 時には非常に便利です。
それから、悉曇も、最近は、Unicodeで使えるようになっていまして、フォントをインストールしないと文字の表示はできませんが 文字列として処理することができるようになっていますので、とりあえず2カ所、悉曇を入力しています。フォントとしては GitHub - MihailJP/Muktamsiddham: a free Siddham font や Releases · googlefonts/noto-fonts · GitHub など、選択肢が提供されている状況です。筆者としても、これを使って色々やるべく準備中です。
あとは、まあ、とにかく画像の確認と入力です。 たとえば目次がついていないものをなんとかするためには、 1頁ずつ見ていくのは大変なので、頁画像一覧をじーっとみて、章の始まりっぽい頁をみつけたらそれを表示して、 それが目的のものであれば、その画像番号と章タイトルをメモしていきます。
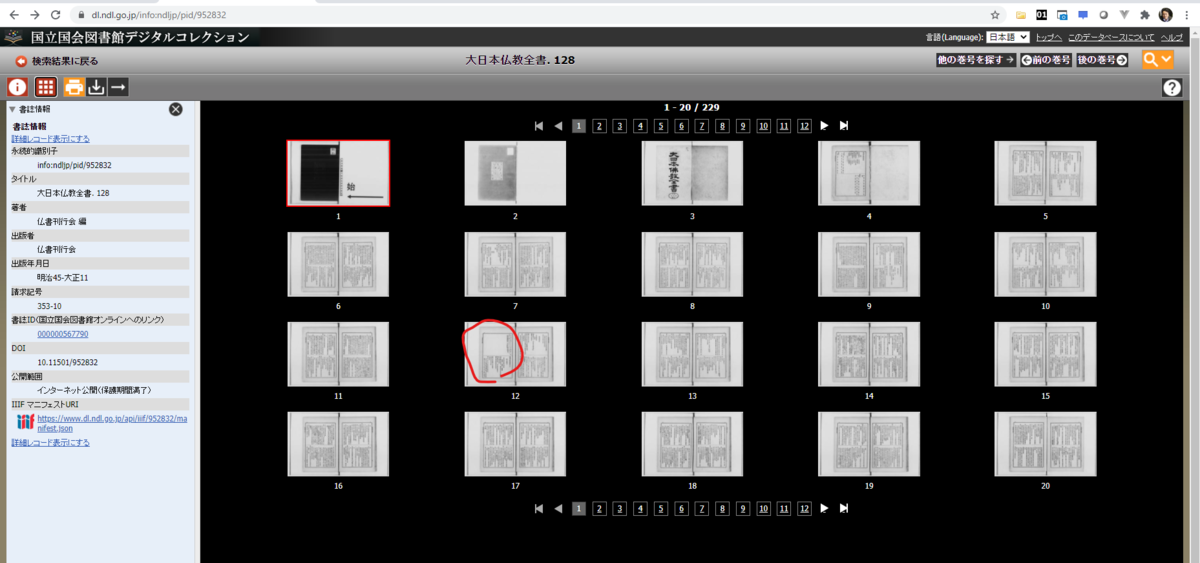
でも、章のタイトルがきれいに出ないものもあるので、そういうものは結局、全ページをめくっていくことになります。 1頁2-3秒くらいですので、まあちょっと集中すればなんとかなります。
というようなことで、まだ作りかけですが、とりあえず一区切りということでこちらにご紹介させていただきました。今後、章タイトルを もう少し充実させる予定ですが、他のデータとのリンクという点ではここまでやればなんとかなるので、 次は処理の方を色々考えてみたいと思いつつ、そろそろ年が明けそうです。みなさま、来年もよろしくお願いいたします。