前回はTEIファイルから地図マッピングをする話でしたが、今回は少し違う角度から取り組んでみます。
最近、JDCatデータのお試し検索サイトというものを作ってみました。
人文社会科学の研究データを総欄できるサイトとして最近運用が始まった
JDCatというサイトがありますが、
こちらで集約して検索できるようにしているメタデータはCC0で公開されていますので、
せっかくのCC0を活かして教材作り等に使えないかということで試しに作ってみたのが
上記のお試し検索サイトです。ちなみにソースコードはこちらですが、
ファセット検索の部分がお手製コードなので非常に微妙ですのであまり
じっくりみないでください…。通常はここは、ElasticsearchとかApache Solr等で
検索して戻ってきたファセットのデータを使うところを、検索自体を
Javascriptの中でやってしまっているので、ファセットの処理も
自分で書いてしまっています。もっとスマートな書き方があると思いますが
ご容赦ください…
何の教材かと言えば、vue.jsの使い方です。vue.jsで何度かサイトを構築してみて
まあまあわかってきたということと、これから若者にJavascriptの勉強を始めてもらうなら
vue.jsかreactだろうということで、とりあえずは vue.jsです。
ただし、vue.jsだけだとデザイン的にはあまりこじゃれた感じにはならないのですが、
ここで出てくるのがveutifyです。これに従ってタグと
スクリプトを書けば、非常に少ないコードでとてもきれいで動的なサイトを
構築できます。
開発環境の構築
ということで、まずはvuetifyの導入からです。これにはいくつかの段階が必要で、
しかも、色々と前提条件を理解した方が本来は良いのですが、最初にここから
入る人もこれからは多いのでしょうから、
「やってみたらできた」というところをとりあえずは目指していきましょう。
vue.jsは、npmというパッケージシステムから使うのが便利(?)です。
もっと良い方法も最近はあるかもしれませんが、とりあえず、比較的枯れたやりかたでも
ありますので、これでいきましょう。
筆者の環境は、Windows 10 にWSL2を入れてそこでUbuntu18 を動かし、Ubuntu 18 に
npm をインストールしています。MacOSの場合は、何もせずともそのまま
「ターミナル」を開くだけでよいと思います。Windows10/11の場合は、
Ubuntu18を入れるところまでは、他のサイトで確認してください。Ubuntu20でも
多分同様にできると思いますが、試していないのでわかりません。
Ubuntu18 を入れると「ターミナル」でUbuntu18を操作できるようになります。
そこで、以下のようにコマンドを入力してエンターキーを押します。
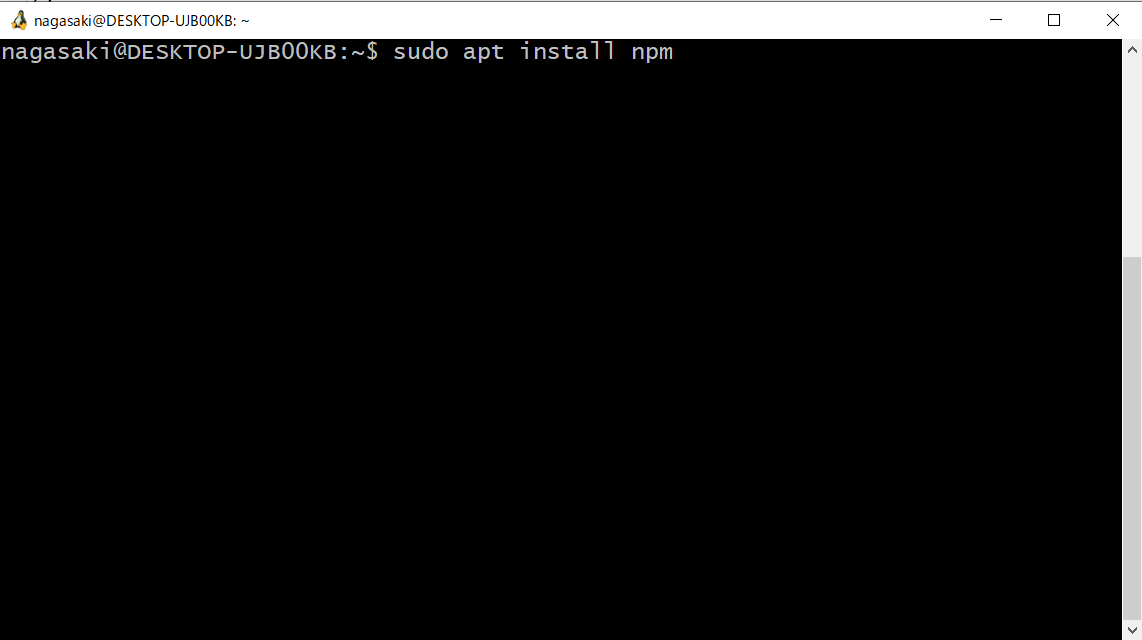
$ sudo apt install npm
そうすると、npmというコマンドが使えるようになります。
その後いくつかのコマンドを入力すると、Vuetifyが使えるようになります。
大体、以下のような感じでいけると思います。
$ sudo npm install vue
$ sudo npm install -g @vue/cli @vue/cli-service-global
ここまできたら、次はこちらのサイトに従って操作すれば、多分以下のコマンドで自分のプロジェクトを立ち上げることができると思います。
$ vue create my-app-test
※ my-app-test のところには自分のプロジェクト名を書いてください。(my-app-test のままでも大丈夫です)
※何か色々聞かれますが、全部そのままリターン(エンター)を押せば大丈夫です。
$ cd my-app-test
※前のコマンドで my-app-test を別の文字列にした場合は、それと同じものをこのコマンドの my-app-test のところに書く
とりあえずここまできたら、次は以下のコマンドを入力して、動作確認をしてみます。
$ npm run serve
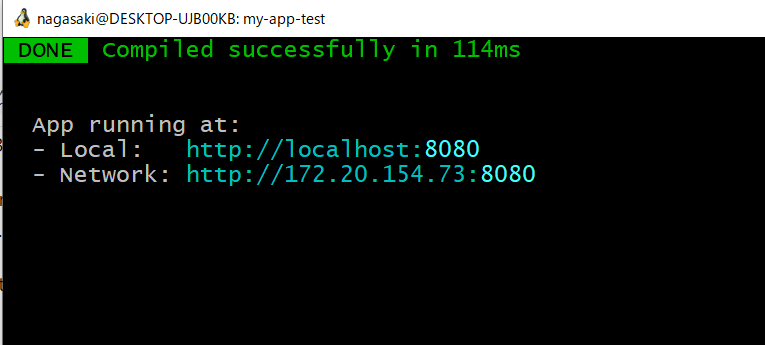
上記のコマンドを打った後は、少し時間がかかりますが、以下のような画面になるはずです。
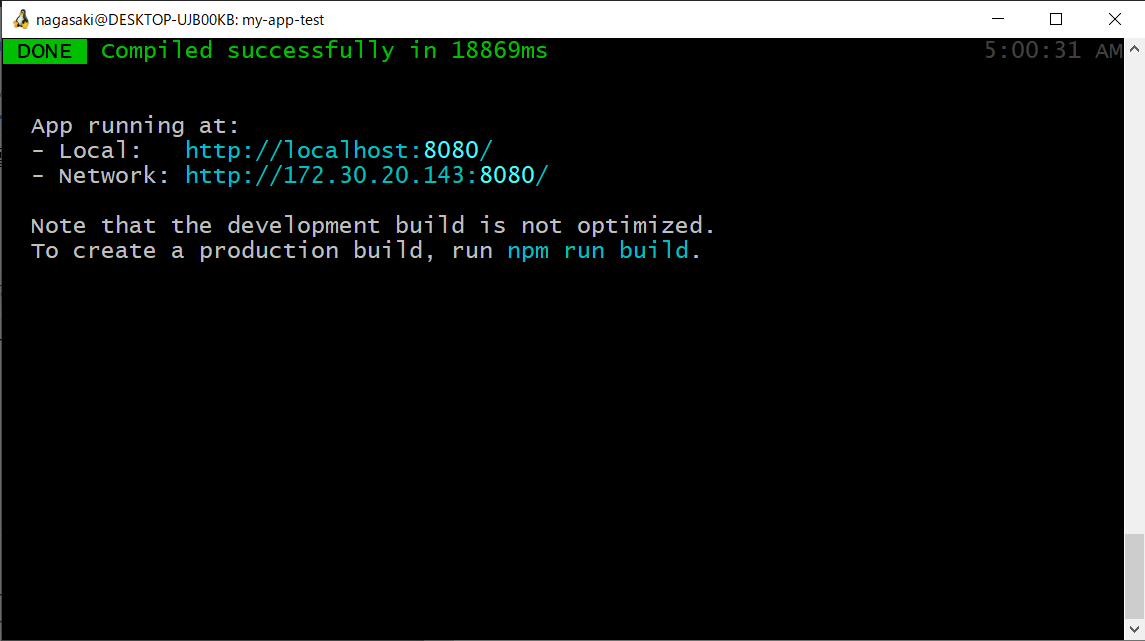
そうしましたら、指示されている localhost の方のURL ( http://localhost:8080/ 等 )にWebブラウザでアクセスすると
以下のような頁が表示されるはずです。
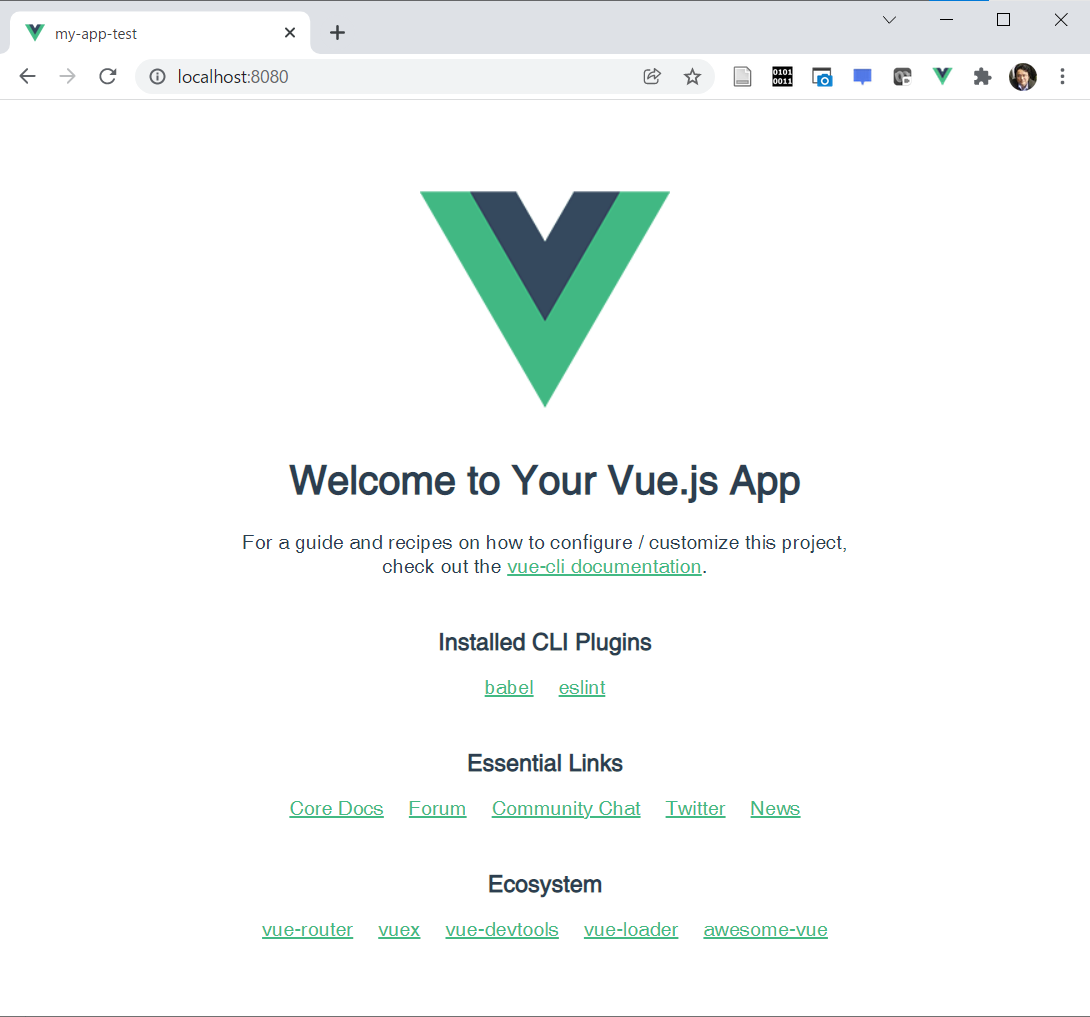
ここまでできたら、Vue.jsのインストールは成功です。次に、Vuetifyをインストールしますので、
コマンドラインに戻ってCtrl - C を押して、コマンドプロンプトに戻ってください。
次に、以下のコマンドを打ってください。
$ vue add vuetify
これで、vuetify を使えるようになったはずです。
もう一度、以下のコマンドを実行してから指定されたURL ( http://localhost:8080/ 等)にアクセスすると、
$ npm run serve
今度は以下のような頁が表示されるはずです。なかなかかっこいい頁ですね。これで準備はOKです。
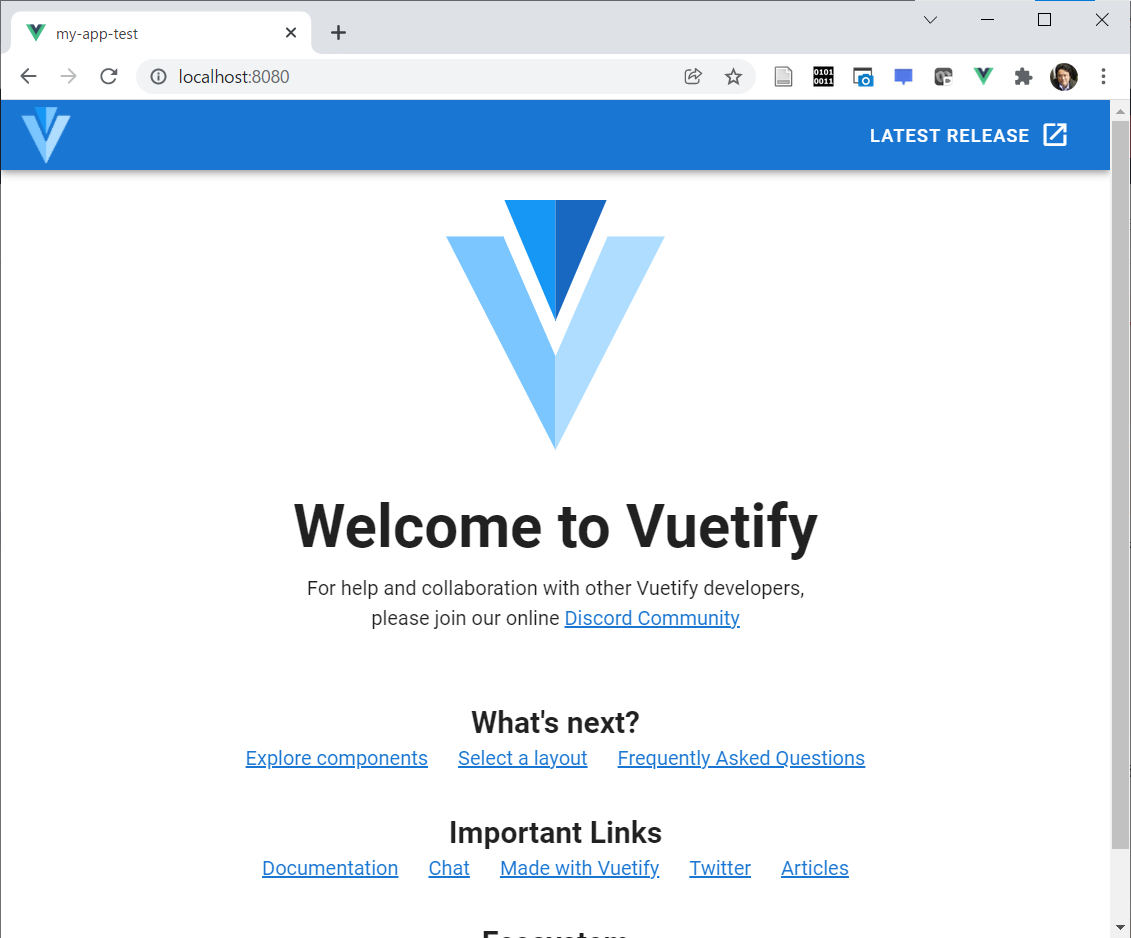
現在は、 my-app-test フォルダ(ディレクトリ)の中にいるはずですので、現在のフォルダ内の
ファイルをウインドウズのエクスプローラー等で一覧してみますと、以下のようになるはずです。
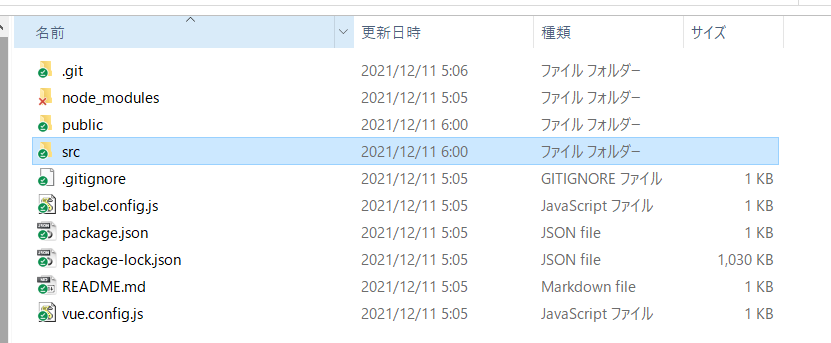
ここに入っているファイル群にプログラムを書いたりモジュールを追加したりすることで、
Vue.js / Vuetifyを活用したサイトを構築できるということになります。
なお、一定の制約はありますが、基本的にここで動くモノはローカルパソコンでも動きます
ので、スタンドアロンアプリのようにして使うこともできます。
それではいよいよ、vuetifyを使ったWeb頁の作成です。上記のフォルダの中の
「src」というフォルダを開いてみてください。そうすると以下のような
ファイル一覧が表示されるはずです。ここで、「App.vue」というファイルを
編集することになります。編集には、VSCodeの利用をおすすめします。
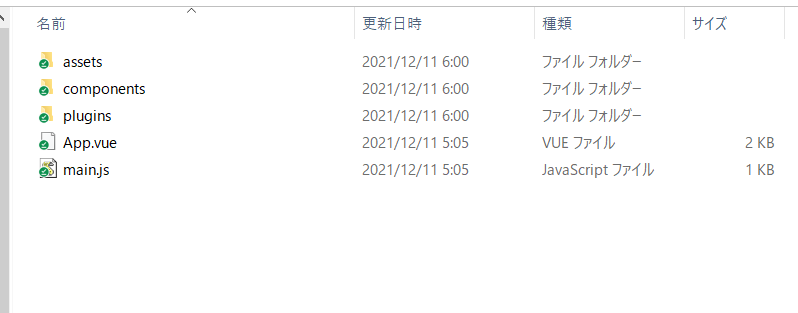
さて、ここでまず、後々の作業を少しだけ楽にするための設定をしておきます。
このファイル一覧にある vue.config.js というファイルをVSCodeやメモ帳等のテキストエディタで開くと以下のように
書き込まれているはずです。
module.exports = {
transpileDependencies: [
'vuetify'
]
}
これに追記をして、以下のようにして保存してください。
module.exports = {
transpileDependencies: [
'vuetify'
],
configureWebpack: {
devServer: {
watchOptions: {
ignored: /node_modules/,
poll: true
}
}
},
publicPath: './'
}
それから、一度 npm run serve をCtrl-c で停止して、もう一度実行してください。
これで、「スクリプトを書き換えると http://localhost:8080/ で開いているWeb頁
がそれにあわせて変更される」ようになりました。
さて、ではさっそく、VSCodeで App.vueを開いて書き換えを試してみましょう。
以下のように、<HelloWorld/>というタグが書かれた箇所がありますので、その一行上に
hello world と書き込んで保存してから、 http://localhost:8080/ をみてみましょう。
<v-main>
hello world
<HelloWorld/>
</v-main>
</v-app>
</template>
そうすると、以下のような感じで「hello world」が
表示されるはずです。このようにして、App.vueを書き換えると自動的に頁が更新されることになります。
これはなかなか便利ですね。
では次に、何か動くものを書いてみましょう。
動くものを少し書いてみる
まずは、
「ボタンを押すと表示される」
というものを書いてみたいと思います。
普通にファイルを開くと40行目あたりからになりますが、
以下のように書いてみます。スクリプトの下に解説を少し書いておきますので
ご参考にしてください。
<v-main>
hello world
<HelloWorld/>
<v-btn @click="testfunc">Push</v-btn>
<div>{{ testdata }}</div>
</v-main>
</v-app>
</template>
<script>
import HelloWorld from './components/HelloWorld';
export default {
name: 'App',
components: {
HelloWorld,
},
data: () => ({
testdata:'',
}),
methods:{
testfunc:function(){
this.testdata = 'This is a test.'
}
}
上記のスクリプトを少し解説しますと、まず、
<v-main>というタグの中で、<HelloWorld/>の次の行に、
ボタン表示するタグを書き (<v-btn></v-btn>)、そこで、クリックするとtestfuncという
関数が動作するように(@click="testfunc")、タグの属性の位置に書いておきます。
それから、次の行には、結果表示のために<div></div>タグを用意した上で、
そこに、変数testdataの中身が表示されるように{{ test data }}
と書いておきます。ここでは 「{{ }} 」がキモです。
次に、変数 testdata をこのタグの中で利用できるように、「 data: () => ({」以下に、
「testdata:'', 」と書き込んでおきます。これは、testdataの変数の型がテキストであることを示しています。
そして最後に、data:() =>({...}), の次に、カンマで区切った後にmethods:{}を書き込み、
さらにそのなかに、関数testfunc を書き込みます。今回は単に、'This is a test.'と
表示するだけのスクリプトを書いてみますが、そのためには、 this.testdata に表示したい
文字列を代入することになります。つまり「this.testdata = 'This is a test.'」ということですね。
これができたら保存して、「Push」ボタンがWeb頁上に表示されたらクリックしてみてください。

それで、上記のようにボタンの下に「This is a test.」と表示されれば成功です。
次に、ボタンを押すたびに表示/非表示を切り替えるようにしてみましょう。
testfunc(){ }
の中に以下のようなスクリプトを書いてWeb頁上で表示/非表示を切り替えてみてください。
testfunc:function(){
if (this.testdata == ''){
this.testdata = 'This is a test.'
}
else{
this.testdata = ''
}
}
これは、this.testdata の内容を判定して表示したり表示しなかったりという処理をしていますね。
これがうまくいけば、とりあえずVuetifyの使い方の基本中の基本はできたはずです。
地図を表示
次に、色々端折って、地図を表示してみましょう。これは前回記事と同じLeafletですが、vue.jsを使っている
今回の環境の場合とは、インストールの仕方も設定の仕方も異なります。
まずは、コマンドラインに戻って、以下のコマンドを実行して vue2 用のleafletをインストールしてみましょう。
$ npm install vue2-leaflet leaflet --save
やや拍子抜けですが、これでインストール終了です。
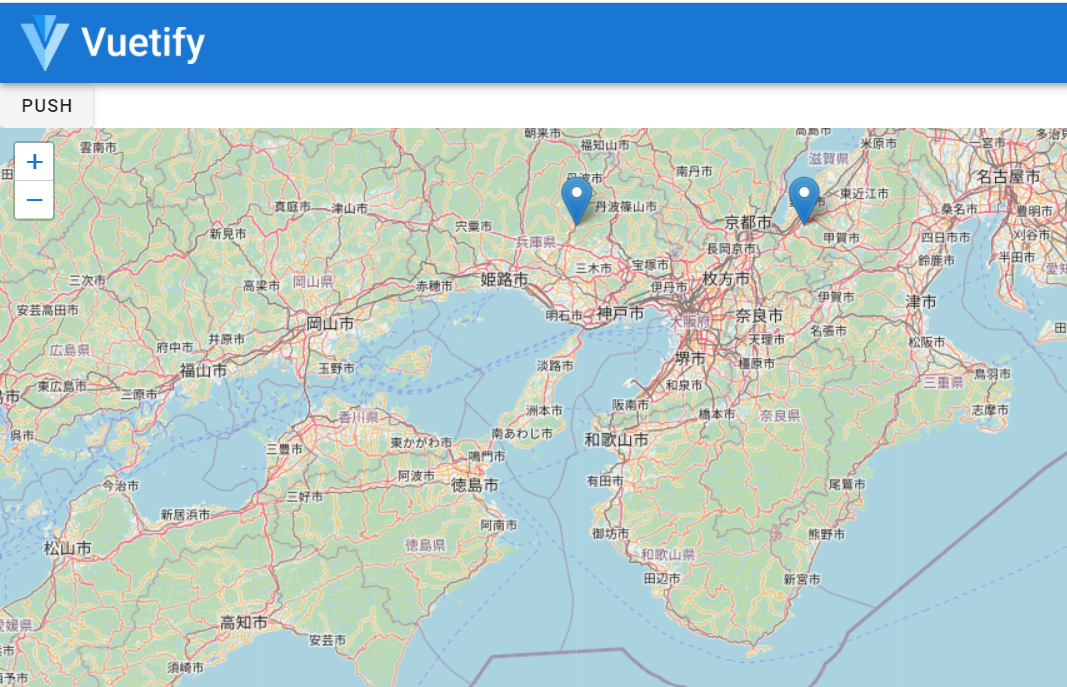
では次に Leafletの地図の表示ですが、必要な情報を今までのスクリプトに追記したものの該当箇所は以下のようになります。地図は
ぐりぐり動かせますのでぜひ試してみてください。
<v-main>
hello world
<HelloWorld/>
<v-btn @click="testfunc">Push</v-btn>
<div>{{ testdata }}</div>
<l-map ref="map" style="height: 600px;" :zoom="zoom" :center="center">
<l-tile-layer :url="url"></l-tile-layer>
</l-map>
</v-main>
</v-app>
</template>
<script>
import HelloWorld from './components/HelloWorld';
import 'leaflet/dist/leaflet.css'
import { LMap, LTileLayer } from "vue2-leaflet";
export default {
name: 'App',
components: {
HelloWorld,
LMap, LTileLayer
},
data: () => ({
url: "http://{s}.tile.osm.org/{z}/{x}/{y}.png",
zoom: 8,
center: [34, 137],
testdata:'',
}),
上記のスクリプトを簡単に解説すると、まず templateタグ内の<v-main>の中に<l-map>...</l-map>として地図の位置と高さなどの
情報を書き込んでおきます。
次に、LeafletのCSSと vue2-leafletモジュールを import します。
そして最後に、 data: () => ({のところで、url:とzoom: と center:のデータをそれぞれ書いています。
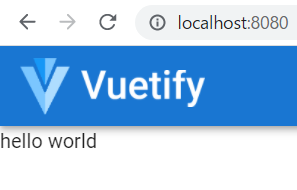
これで、地図が表示できるようになりましたが、さらに、先ほどの Pushボタンや VuetifyのWelcome画面がまだ残っていますね。
とりあえず、Vuetify のWelcome画面だけは消してしまいましょう。そのためには、3カ所、削除する必要がある場所があります。
どれかを残してしまうと、Vueは「不整合だ」といってエラーを表示してくれますので、3つとも削除します。
まずは、<HelloWorld/> タグ、それから、「import HelloWorld from './components/HelloWorld';」の行、
それに加えて、「 components: { 」の次の行にある「HelloWorld,」です。これらを削除すると以下のようになりますね。
<v-main>
hello world
<v-btn @click="testfunc">Push</v-btn>
<div>{{ testdata }}</div>
<l-map ref="map" style="height: 600px;" :zoom="zoom" :center="center">
<l-tile-layer :url="url"></l-tile-layer>
</l-map>
</v-main>
</v-app>
</template>
<script>
import 'leaflet/dist/leaflet.css'
import { LMap, LTileLayer } from "vue2-leaflet";
export default {
name: 'App',
components: {
LMap, LTileLayer
},
data: () => ({
url: "http://{s}.tile.osm.org/{z}/{x}/{y}.png",
zoom: 8,
center: [34, 137],
testdata:'',
}),
これで、以下のように、Pushボタンやテキストの「hello world」を残しつつ、その直下に地図が表示されるはずです。
だいぶいい感じになってきましたね。
v-forを試してみる
次に、仮想DOMを象徴する便利な書き方であるところの v-for を試してみます。これは、たとえば
複数マーカーを地図上に簡単に表示するために有用なものですが、応用性が高いので、
その基本的な書き方のみをまずはみてみましょう。
ちょっと長いですが、以下のように追記をしてみます。
</l-map>
<ul v-for="eachdata in testdata" :key="eachdata.id">
<li>{{ eachdata.name }}</li>
</ul>
</v-main>
</v-app>
</template>
<script>
import 'leaflet/dist/leaflet.css'
import { LMap, LTileLayer } from "vue2-leaflet";
export default {
name: 'App',
components: {
LMap, LTileLayer
},
data: () => ({
url: "http://{s}.tile.osm.org/{z}/{x}/{y}.png",
zoom: 8,
center: [34, 137],
testdata:[],
}),
methods:{
testfunc:function(){
if (this.testdata.length == 0){
let datalist = []
let datatext = {}
for (let n=0;n<5;n++){
datatext['id'] = n
datatext['name'] = 'name:'+n
datalist.push(datatext)
datatext = {}
}
this.testdata = datalist
}
else{
this.testdata = []
}
}
}
};
</script>
追記をしているのは、まずは <template></template>の中の以下のタグです。v-forを用いることで
配下のタグ等に関して繰り返し処理ができるようになります。
<ul v-for="eachdata in testdata" :key="eachdata.id">
<li>{{ eachdata.name }}</li>
</ul>
次に、date: ()の中に書き込む事項です。ここでは、これまでテキスト型であったtestdata:を
配列型に書き換えています。「testdata: []」として配列型で初期化しています。
それから、「if (this.testdata.length == 0){ 」の行の後に、今回の処理を行うための処理を書き込みます。
ここでは、v-forに書き込むためのデータを用意しています。v-forのおそろしく面白いところは、
Javascriptで構築した配列やObject(Pythonで言うdictとかPHPで言う連想配列と考えてください)を、
繰り返しも含めてHTMLに表現できてしまうところです。…といっても何を言っているのかよくわからない
かもしれませんので、この例を用意しています。
少し上に戻って、<ul v-for="eachdata in testdata" :key="eachdata.id">のタグをみてみると、
testdata という変数(これはlist)から eachdata を取り出す、という処理をしており、さらに、
:key に対して、eachdata.id としてeachdata Objectのidキーをあてていることになります。
さらに次の行 <li>{{ eachdata.name }}</li> を見ると、 {{ }} の中に、eachdata Objectのnameキーを
記述しています。つまり、
this.testdata = [{"id:"01","name":"good"},{"id:"02","name":"wonderful"},{"id:"03","name":"excellent"}]
というような感じの、Objectを要素とする配列をthis.testdata (data: () => {以下にある変数 testdataを指している)に入れれば、それが上記の v-for属性のついたタグのところに
入力されることになります。それを、一つずつ書くのではなく、とりあえず for でまわしてデータを
構築しているのが、以下の箇所です。
if (this.testdata.length == 0){
let datalist = []
let datatext = {}
for (let n=0;n<5;n++){
datatext['id'] = n
datatext['name'] = 'name:'+n
datalist.push(datatext)
datatext = {}
}
this.testdata = datalist
}
else{
this.testdata = []
}
}
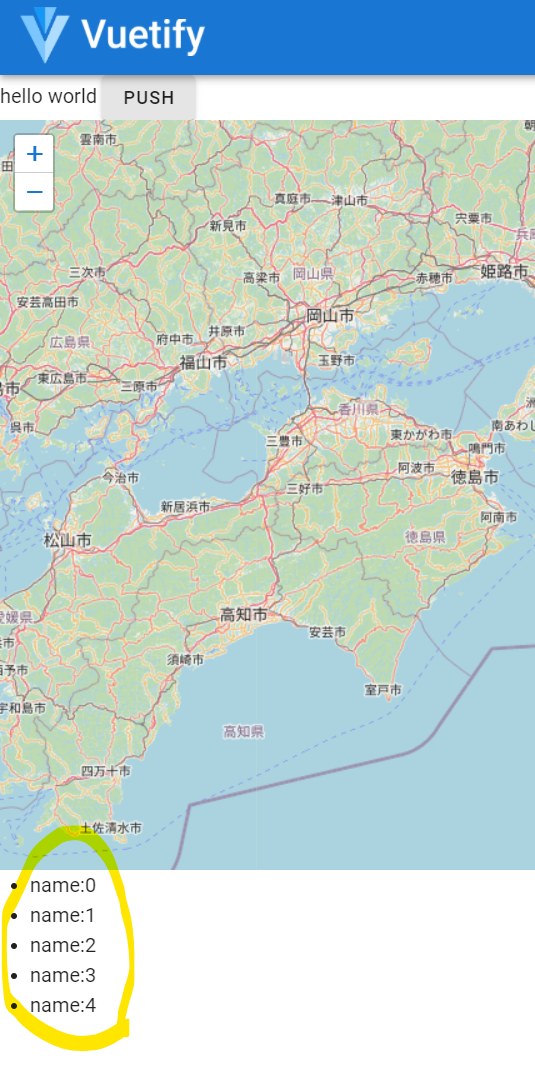
ここでは、もしthis.testdataが空ならば(空であることを判定するために、this.testdata.length で、この配列内に要素が存在するかどうかを判定しています)、
datatextというオブジェクトを作って一つずつ配列 this.testdataに入れるという操作を5回繰り返し、一方、もし空でなければ、this.testdata を空にする(ただし
これは配列なので空にするためには [] を用いる)、という処理をしています。この一連の処理を、ボタンを押す=testfunc関数がclickで動作するたびに
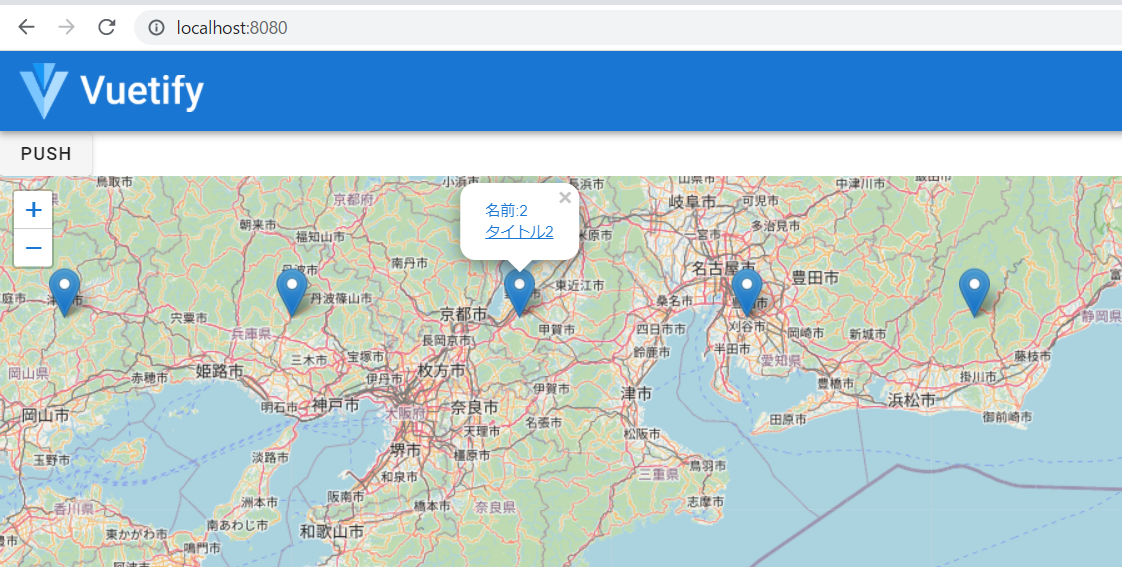
行う、というのがこの処理です。これをうまく書けると、以下のように、Pushボタンを押すたびに5行のアイテムが表示されたり消えたりを繰り返します。
というわけで、やや長くなってしまいましたので一旦ここら辺で区切ります。次回はまた近日中に、ということで
よろしくお願いいたします。