日本の古典籍のオープンデータのお話、ずいぶん間が空いてしまいましたが、その間、何もしてなかったわけではありません。ちまちまと開発を続けておりまして、しかしご報告を書く時間がなかなかとれないという状況でした。
今も、他にも色々しなければならないことがあるのですが、本件を少しまとめて発表しようと思うようになったので、その前段階としてちょっと近況をご報告します。主に、D3.jsを組み込んだという話と、国際的に流行しつつあるデジタル画像流通プロトコル、IIIFに対応させてみた、という話です。
D3.jsの組み込み
ということで、まず、D3.jsを組み込んだ、「タグ連想検索」を作りました、という話です。名前がちょっと仰々しいですが、要するに、関連しそうなものを連想的にたどっていけるようにする、というものをテキストデータとリンクで表示するようにしていたのですが、それをD3.jsに読み込ませるようにしただけのものです。ただ、組み込むにあたり、D3.jsのサンプルをちょっと修正して使っています。修正したのは、各ノードの大きさを個別に変更できるようにしたという点です。あとはほぼそのまま使っていると思います。

私のようなDIYレベルのプログラマの場合、D3.jsを組み込むポイントは、
- サンプルにあるjavascriptやcssのファイルをとにかくそのまま組み込んでみる。
- とにかくうまく読み込ませることができるJSONデータを生成する
という2点かと思います。これだけで色々面白いものを作れてしまうというのがD3.jsの素晴らしいところだと思います。
実は、このサンプルはしばらく前から別のシステム(ITLR等)で使っていて、これを使った最初の発表は、多分、2014年の夏、ウィーンで開催された国際仏教学会、ITLRのプロジェクトを紹介した時だったのではないかと思います。その後いくつかのシステムで利用してみながら、課題の一つとして、ノードのサイズと線の太さを変えられるようにしなければ…ということを感じておりました。今回の「タグ連想検索」では特にノードのサイズが重要だったので、これだけはなんとかしてから公開、と思っていたので、少し時間をかけてしまいましたが、まあなんとか実現できました。これに読み込ませるJSONデータもあわせて形式を修正しています。
「連想」と言っていますが、今回は、元データの関係上、それほど複雑なことをしているわけではありません。タグは1つの頁に複数登場しているものもあれば1つしかないものもあり…というような状況で、何らかの関係を記述するのはなかなか難しい状況です。今回の場合、同じ頁に登場するタグ同士は関係が深く、隣の頁に登場するタグは深くないけど関係があり、さらにその隣の頁に登場するタグはもう少し浅い関係があり…ということで、5頁以内に登場するタグは関係があるかも、という前提で関係データを作りました。
作成した関係データは、いったんデータベースに入れておいてインデックスをはって高速に検索できるように用意しておき、ユーザから検索クエリが来たらそれにあわせて、適宜、適切なデータを取り出してJSONデータ化する、という風にしています。(最初は、システムの移植可能性を考慮してテキストファイルを毎回開いて検索するようにしていましたが、どうにもデータ取り出しに時間がかかってしまうので、諦めてデータベースを使うことにしました。)関係データをJSONデータ化するにあたっては、まず、計測した結果を連想配列として整理し、その後、連想配列をJSON形式に変換するPHPの関数を使ってJSONデータに変換するという手順になっています。なお、PHPではオブジェクトからJSON形式に変換することもできるようなので、若者はオブジェクトを使うとよいのではないかと思います。
とういわけで、あとは、以前に作ったタグ検索システムをちょっと組み合わせて、ノードをクリックすればタグ検索結果が表示される、というものも組み込んで、まあ大体ここまで来ています。あと1つ2つ、機能を追加したいのですが、まだちょっと手が回りません。
あと、根本的な問題として、タグと画像頁との対応がちょっとずれてしまっているところがあるようで、今後はそこの精度を上げるというか、ずれが生じないようなタグ付与を期待したいところです。
IIIFへの対応
IIIF(トリプルアイエフ, International Image Interoperability Framework, 国際画像交換フレームワーク)というのは、名前の通り、Web上でデジタル画像をやりとりする際の国際的な枠組みです。簡単に言うと、サーバ側の負担を大幅に増やして、クライアント(Webブラウザ)側から簡単に画像にアクセスできるようにしようという枠組みです。IIIFのルールに従ったURLをサーバに渡すと、サーバは画像を加工(切り出し・回転・サイズ変更など)してクライアント側に返してくれます。
IIIFには、スタンフォード大学がかなり力を入れているようですが、コミュニティ参加機関を見る限りでは、重要機関の多くが参加するようになってきているようで、これに(も)のっておかないと後で大変になってしまうのではないかという感じがあります。個人的に、おおっ、となった参加機関としては、オックスフォード大学ボドリアン図書館、フランス/オーストリア/デンマーク/ニュージーランド/ノルウェイ/イスラエル/セルビア/ウェールズ国立図書館、英国図書館、Europeana、DPLA、ウェルカムトラスト、テクストグリッド、あたりですが、他にも色々な有名関係機関が名を連ねています。(まだメジャーなところのすべてではない、ということにも注目しておきたいところですが、もちろん、参加機関に名を連ねなくてもこれに対応することはできます)
ちなみに、1年ほど前に参加したパリでのEuropeana Techでこれをよく知る機会を得たのですが、すでに当然のものとして語られていて、当時すでにプロトコルはバージョン2となっていました。最近は、デジタル・ヒューマニティーズ関連の会議でもちょこちょこ出てくるようになっています。基本的に、画像方面は疎いので、ふむふむ、と思って翌月には自分のところでちょっとサーバを動かしてみたりしました。下記、2015年12月にDigital Humanities in Japanという Facebookのグループに掲載したものに若干手を加えて再掲します。
IIIFについてもう少し具体的に見ていきますと、基本的には、
(1)画像を表示する際にURLで画像の表示形態を指定するルール(image API)
(2) (1)を前提として画像のメタデータを効率的に共有するルール(presentation API)
から成っているようです。たとえば、
先日スタンフォード大学で公開された国絵図の高精細画像
http://gigazine.net/news/20151213-omi-kuni-ezu-stanford/
にもこのIIIFが採用されていました。
これがどういう風になるかといいますと、たとえば、
長辺を1000ピクセルで表示
.../full/!1000,1000/0/default.jpg
長辺を500ピクセルで90度回転させて表示
.../full/!2000,2000/90/default.jpg 
一部を指定して切り出して表示
.../7400,9500,1000,1000/!1000,1000/90/default.jpg 
というような感じのことができます。
これだけですと、URLまでいちいちいじらない一般利用者にはあまり縁のなさそうな話ですが、これは、色々な画像ビューワを作る際に大きく影響してきます。つまり、IIIF対応画像ビューワがあれば、どのサイトに置いてある画像でも同じように閲覧することができるようになります。さらに言えば、たとえばバーチャル博物館のような仕組みを作る際にも、IIIFの配信形式に対応した画像を対象とするなら、、IIIFに対応した表示機能を用意するだけで世界中で公開されているIIIF配信形式に対応した画像を取り込んで利用することができるようになります。IIIFの配信形式に対応した画像の公開がある程度広まっていけば、他にも様々な活用が可能となっていくことでしょう。(IIIF登場以前ですが、キュレーター養成カリキュラムでバーチャル博物館作成Webシステムを作って使った話を聞いたことがありまして、そういうものもIIIFの配信形式に対応した画像が増えてくれば一気にブレイクするかもしれませんね)
すでに、フリーでの実装がいくつか公開されておりまして( http://iiif.io/apps-demos.html )、さらに、日本でもデジタルアーカイブシステムを作っている大手の某社がIIIFに近々対応すると聞いております。仕組み自体は複雑なものではありませんので、仕様書に「IIIFに対応すること」と書くだけで対応できる可能性もあります。
さて、筆者はDIYプログラマであり発注担当者でもあるので、当然、自分でも一応やってみなければ、という思いに駆られるわけです。1年程前に一度試してみたのですが、そのときに使った画像データだと、効果的な感じにするのにちょっと手間がかかりそうだったのでブログに書いたりしなかったのですが、このたび、国文研データセットでImage APIの方を試してみたところ下記のような感じになりました。
横幅500pxで表示
http://www2.dhii.jp/loris/NIJL0010/099-0127/099-0127-00023.jpg/full/1000,/0/default.jpg

斜めに少し傾けて横幅は400pxで
http://www2.dhii.jp/loris/NIJL0010/099-0127/099-0127-00023.jpg/full/800,/22.5/default.jpg

右下のカエルだけを切り出して横幅800pxで表示
http://www2.dhii.jp/loris/NIJL0010/099-0127/099-0127-00023.jpg/pct:60,65,18,23/800,/0/default.jpg

サーバ側は、大きな画像を1枚用意しておけば、あとは、クライアント側からリクエストされたURLに応じてサーバが画像ファイルを加工して送出してくれるようになっています。これだけだと一般ユーザからはあまり面白くないかもしれず、どちらかと言うとソフトウェア開発者にとって面白い機能なのですが、一般ユーザでも、URL指定するだけでサーバ上の画像を切り出して提示できるということは、たとえば下記のようなことが可能になります。この場合、同じ座標で切り出してみましたが、画像撮影が上手にできているせいか、まあなんとかうまくできている感じです。
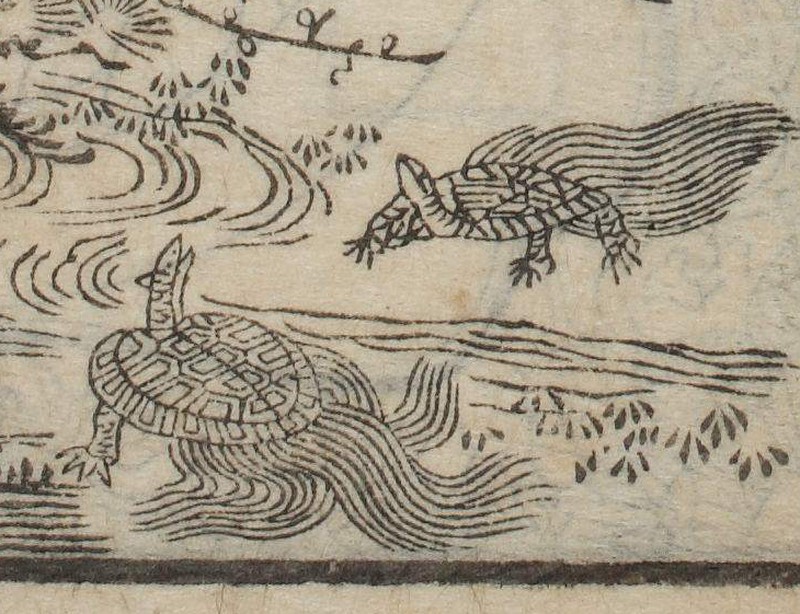
例:寛政3 (1791)年刊と享和4 (1804)年刊の武鑑の口絵に出てくる亀を見比べてみる
http://www2.dhii.jp/loris/NIJL0307/MIT-Y01201-140/MIT-Y01201-140-00004.jpg/pct:35,70,13,15/800,/0/default.jpg
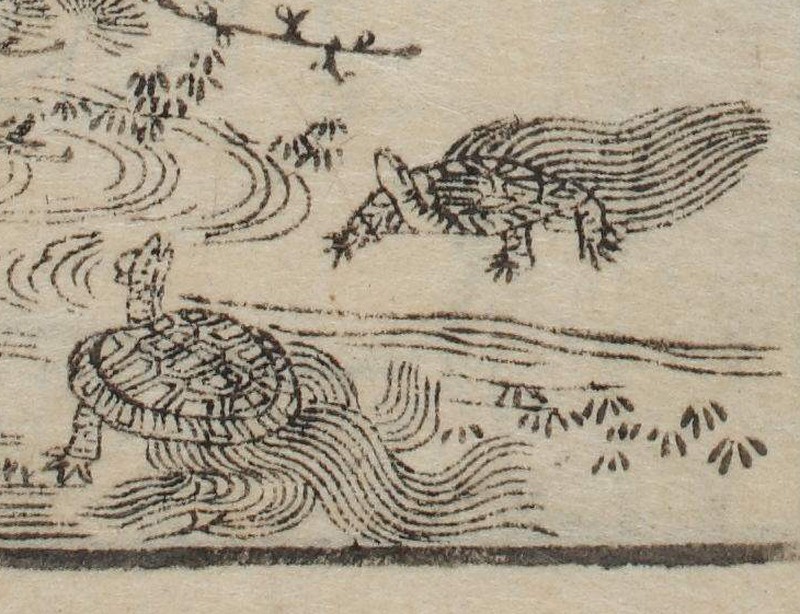
http://www2.dhii.jp/loris/NIJL0308/MIT-Y01201-149/MIT-Y01201-149-00004.jpg/pct:35,70,13,15/800,/0/default.jpg
で、違ってる箇所をさらに拡大してみると…
http://www2.dhii.jp/loris/NIJL0307/MIT-Y01201-140/MIT-Y01201-140-00004.jpg/pct:36,80,4,5/400,/0/default.jpg
http://www2.dhii.jp/loris/NIJL0308/MIT-Y01201-149/MIT-Y01201-149-00004.jpg/pct:36,80,4,5/400,/0/default.jpg


さらに、座標がちょっとずれますが、寛政11 (1799)年刊の亀は以下のような感じです。
http://www2.dhii.jp/loris/NIJL0306/MIT-Y01201-146/MIT-Y01201-146-00002.jpg/pct:35,72,13,15/800,/0/default.jpg

このように、普通のユーザがブログを書いたりする時でも、画像URLの書き方のルールさえ知っていれば、割と自由に画像の部分引用ができるようになります。画像URLの書き方が面倒だ…と思われる方もおられると思いますが、もう少しお待ちいただければ、簡単に書けるような仕組みもご提供しますので…
ところで、ここまで来ると、開発系の人はむずむずしてくると思いますが、サーバ側にインストールしてみたのは、リストされているもののうち、lorisというソフトウェアです。これは、Jpeg画像でも使えて、Pythonで書かれていて、Apacheを介してデーモンとして動かせるので、お試しとしては導入が楽かと思い、使ってみています。あと、気になっているのはdigilibなのですが、まだ試せていないので、どなたか試用レポートをあげていただけるとありがたいなと思っております。
lorisの導入は、上記のWebサイトに書いてある通りです。基本的に特に難しいことはないと思いますが、サーバ側に必要なライブラリ等をすべて用意するのに若干手間取りました。そこさえクリアできれば、あとは難しいことは特にないと思います。
IIIFは、簡便なユーザインターフェイスをクライアント側に用意するだけで画像の提示や切り出しを色々な形で(再掲: Image APIを参照)できるようになるということで、様々な応用が期待されるところです。私もそのうち、これを活用した面白いソリューションを提供したいと思っています。






{kind=link}
{kind=link}
{kind=link}