先日、文部科学省から、増上寺三大蔵がユネスコ「世界の記憶」における国際登録の登録申請案件に推薦されることになったとのお知らせがありました。
文部科学省のサイトによれば、ユネスコの「世界の記憶」は、以下のようなもののようです。
世界的に重要な記録物への認識を高め、保存やアクセスを促進することを目的に、ユネスコが1992年に開始した事業の総称。本事業を代表するものとして、人類史において特に重要な記録物を国際的に登録する制度が1995年より実施されている。
そして、この「世界の記憶」の現在の登録状況は、
現時点で429件が国際登録、56件が地域登録されている。日本からは国際登録に7件、地域登録に1件が登録されている。
とのことです。
ここで話題にしている増上寺三大蔵は、この文科省のサイトでは以下のように説明されています。
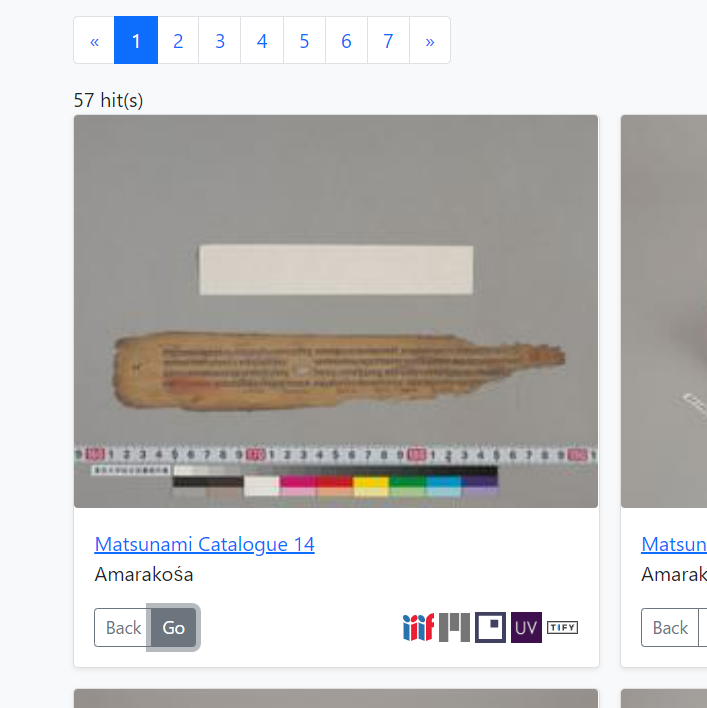
17 世紀初頭に徳川家康が日本全国から収集し、浄土宗の大本山である増上寺に寄進した、三部の木版印刷の大蔵経(※)。現代の仏教研究の基礎を為すという文化史上はもとより、漢字文化、印刷文化の観点からも貴重な史料。全て国指定重要文化財。 ※「大蔵経」…5,000 巻を超える仏教聖典の叢書。
家康が集めて寄進した、という経緯もなかなかすごい話で、当時はまだ入手がかなり困難であった大蔵経を、3セットも、しかも異なる時代・地域で印刷されたものを集めたというのもすごいことですが、これに加えて、天海僧正に木活字版の大蔵経を編さんさせたり(このあたりはまだよく理解していなくて、家康は支援していただけ?)もしていたようです。(これは寛永寺で実施されたようで、天海版として現在も各地の古寺名刹の経蔵に納められているそうです。ColBaseで刊記がみられたり、国文学研究資料館で妙法蓮華經観世音菩薩普門品の全頁画像が見られたりします。)
この三大蔵(木版印刷で、宋代に刊行された思渓版、元代に刊行された普寧版、高麗で刊行された高麗版再雕本)が現代の仏教研究の基礎を成す、というのは、直接には、明治14年から18年にかけて刊行された大日本校訂大蔵経(縮刷蔵)の校訂編纂にこの三大蔵が使われたからなのです。お寺の宝である大蔵経ですので、おいそれと人に見せられるものでもなく、そもそも分量が膨大ですので(5000巻以上になる)、それを3セット広げて確認するだけでも相当な時間とそれなりの場所を必要とします。日常業務に加えてこれを3セット全部出して、編纂作業をしにくる人たちが扱いやすいように用意する、ということを考えただけでもかなり膨大な作業量になってしまいそうです。実際のところ、お寺が大切に所蔵してきた大蔵経を、単なる複製ではなく編纂に供した例は国内では他にはあんまり思いつきません。獅谷白蓮社の忍澂上人が1702年から5年かけ、若者達を動員して建仁寺の高麗版(現在は焼失)を黄檗版(鉄眼版とも。主に嘉興蔵を模し、日本で広く普及した整版。)と一通り比較した、という話は残っていますが、校正録や一部の経典を刊行したくらいのようであり、大蔵経全編を刊行した、というわけではなさそうです。また、大蔵経全編を一人で全部写経した色定法師という大物もおられますが、宋版大蔵経一つをみながらだったようですので、3セットも並べるというほどの大事ではなかったかもしれません。
さて、そのようなことをどうやって実現したのか、というところで出てくるのが、増上寺七〇世であった福田行誡上人です。 行誡上人は様々なご活躍をされた人ですが、その偉業のうちの一つに、この大日本校訂大蔵経(縮刷蔵)の刊行事業があります。この事業は天台宗本山派修験道の大先達であり 政府の役職にあった島田蕃根と共に推進したようで、島田蕃根の事績を調べると縮刷蔵の刊行に関する情報が色々出てきますが、 この事業は、廃仏毀釈や増上寺大殿の放火による焼失などの苦難から立ち直るなかで、おそらくはこれまでどこもやったことがないような 大変な事業を、弘教書院を設立するという形で引き受けたようです。『島田蕃根翁』によれば、
最初は弘教書院を京橋山城町に置きましたのを、行誡上人の好意に依つて増上寺大門前の源興院に移し、此處で校合を始めることになりました
とのことで、ここに三大蔵を持ち出して作業しと思われます。自らの宗派のみならず、広く他宗派の僧侶にも集まってもらって編纂を行ったようで、『島田蕃根翁』には 参加者の名前もリストされています。ちょっと長いですが、文字起こししたものを以下に貼り付けておきます。ただ、これでも全員ではないそうです。
- 東京芝區愛宕下銭照院寄寓眞言宗居士 飯島 道實
- 美濃國武儀郡高野邑臨済宗永昌寺徒弟 東海 玄虎
- 美濃國眞島郡垂見邑同宗佛土寺徒弟 桑 宜動
- 東京築地眞宗應善寺住職 松岡 了厳
- 近江國蒲生郡豊浦邑天台宗東南寺住職 櫻木谷 慈薫
- 武藏國橘樹郡神奈川町眞宗長延寺住職 雲居 玄導
- 駿河國益津郡郡村臨済宗慶全寺前住徒弟 天野 宜格
- 豊前國宇佐郡日足村曹 洞宗地蔵院前住徒弟 佐藤 道悟
- 東京下谷區南稲荷町眞宗南松寺住職 櫻木谷 範隆
- 信濃國南佐久郡跡部村浄土宗西方寺住職 森 亭闇
- 紀伊國海部郡湊村天台宗明王院住職 蘆津 實全
- 東京赤坂臨済宗種徳寺住職 朝木 英叟
- 近江國滋賀郡比叡山坂 本村天台宗正觀院住職 岩本 榮中
- 伊勢國安濃郡垂見村眞言宗成就寺住職 牧 政純
- 遠江國榛原郡牧谷原士族 伊佐 岑満
- 上野國勢多郡大胡町浄土宗養林寺住職 月性 豊民
- 上總國長柄郡高洲驛日蓮宗實相寺住職 守本 惺亮
- 駿河國富士郡大鹿村日蓮宗三澤寺住職 齋藤 日一
- 武蔵國南葛飾郡亀戸村眞言宗普門院住職 千葉 賢永
- 三河國碧海郡河野村眞宗東派宗園寺衆徒 太田 祐慶
- 山城國紀伊郡伏見同宗西方寺副住職 兼松 空賢
- 丹波國與謝郡須津村臨済宗江西寺徒弟 外山 義文
- 東京芝公園地廣度院住職 千葉 寛鳳
- 飛騨國大野郡大名田村眞宗入寺住職 平野 素藏
- 同國益田郡馬瀬村同宗桂林寺住職 日野 厳了
- 美濃國本巣郡文殊邑曹洞宗成泉寺住職 古田 梵仙
- 越後國岩船郡平林驛同宗千眼寺住職 山本 法泉
- 東京築地眞宗敬覺寺住職 大江 凝玄
- 摂津國有馬郡三田村曹洞宗心月院住職 蘆浦 默應
- 備中國淺口郡柏島村天台宗福壽院住職 實相 圓隨
この一大事業が比較的短い期間で刊行に至ったということは、それだけ関係者の力が集約されていたということでもあろうかと思います。(このあたりの記述は主にこちらの松永知海先生・梶浦晋先生の記事に拠っています)
ちなみに、なぜ縮刷蔵と言われるのかといえば、懐に入るハンディなものを作ろうとしたためのようです。結果として字が小さくてちょっと読むのが大変なものになってしまった感もありますが、サイズ感を見ていただくと大体以下のような感じです。


ちなみに、この編纂にあたっては、上記の『島田蕃根翁』では以下のように記述されています。
校合の順序校合には、種々方法を考へましたが、大躰は、高麗藏に依ることとし、即ち高麗藏を原稿として、其れに 宋藏、元藏、明藏の三藏を對照して、校訂することとし、若し増上寺の元藏が缺けて居れば淺草淺草寺の元藏を對照して之を補ひ、又、増上寺ので缺けた處があれば、忍澂師の校正本を以て之を補ふこととし、略ぼ仕組は出来ましたので、まづ、一人が大きい聲で高麗藏を讀むと、三人の人が其側で、元藏、宋藏、明藏の三つを見て居て、「それ缺けて居る」「此方には斯様ある」と云ふ様に、双方で相違した點を謂ひ立てる、直に筆を執つて、原稿の麗藏の上に、其由を書き付ける、中には、長行と偈頌と違つて居るものもあれば、全く文字の無い所もある、四本相對しても、全く解らぬ時には、□を付けて後日の識者を待つこととし、それでも、何ぞ、外に流布した本に、参照して見るべきものがあつた時には、其を書き加へて、「今按」の二字を加へ、又、全く参照すべきものもなく、而かも意義の通り安いものは、「疑何誤」「恐當作何」と書いて後人の爲に便利を謀りましたか、此時などには、校訂者に博識の人がほしかつたのです、今、當時、校合者の爲た仕事の順序を云へば、 第一業 校本刪補 第二業 句讀 第三業 麗、宋、元、明四本對校 第四業 再校 第五業 印刷對校 此の通りにしていきました
当時は部数限定でそれほど広まらず、結果として、その後しばらくの時を経て、大学院生が師匠に「縮刷版は入手が難しいからなんとかならないか」と訴えるに至り、それも大正新脩大蔵経刊行の動機の一つのなったようですが、それはまた次の話になります。
大正新脩大蔵経刊行に関しては、すでにこちらのブログ記事にかなり書いておりますので、そちらをご参照ください。大正新脩大蔵経は、縮刷蔵の本文や校異情報を引き継いでいる部分もあるようですが、増上寺三大蔵を改めて踏まえたようで、そのようにして刊行された大部の大蔵経が、世界中の研究図書館に所蔵され、標準的に参照される漢文仏典として広く活用されるようになりました。
この件にはさらに続きがありまして、この大正新脩大蔵経が、筆者もお手伝いしているSAT大蔵経データベースや、台湾で推進されているCBETA大蔵経といった、デジタル時代の仏教学研究基盤を支える重要な要素になります。特に重要だったのは、ある文献のある箇所、というのを指定し共有し議論する際に、大正新脩大蔵経における位置情報を利用できることです。世界中の多くの図書館に所蔵されているために現物の確認が容易であり、また、それまでの実績から、研究論文等でも同様に参照されてきたため、デジタル時代の研究基盤として移行していく際に情報共有のための基盤になったのです、学術情報流通の文脈で言えば、すでに識別子がテキスト単位・頁単位・段落・行単位等で付与されている上に、デジタル以前の論文にも識別子が記載されていて、デジタルデータとして入力すればその識別子を用いて機械的に接続できてしまう、のです。いわば、DOI以前のObject Identifierになっているわけです。実はこれは聖書学でも同じような状況で、西洋古典学でもCTS (Canonical Text Services) というのが以前から用いられていますので、古典学では驚くほどのことではなくて、むしろ、日本の古典作品も頑張りましょう、という話なのですが、それはともかくとしまして、このようにしてデジタル研究基盤を支えるプロトコルが大正時代から用意されていて、それを可能にしたのが増上寺三大蔵だった、ということなのです。また、仏典は、仏教研究だけでなく、様々な研究において参照されることがあります。その場合、その内容だけでなく、参照しようと思うような信頼性を有することも重要なのですが、そのような意味でも、増上寺三大蔵に基づいて編纂された、ということがその信頼の基礎に置かれているように思います。
ということで、ちょっと長い割に内容が薄くて恐縮ですが、増上寺三大蔵のありがたみについて、思うところを述べさせていただきました。自分は仏教学を基礎にして仕事をしていますので、日々、このことを忘れることなく取り組んでおりまして、それがユネスコの記憶遺産に申請されることになったのは、たいへんありがたいことであると思っており、ここに至る努力と、これからさらに登録に向けて進めてくださる関係者のみなさまには深く感謝する次第です。